MiniMax M2.7: un modelo orientado a la autoevolución e ingeniería de software
MiniMax presenta M2.7, diseñado para operar agentes autónomos, optimizar su propio entorno de ejecución y alcanzar un 56.22% en el benchmark SWE-Pro.


El 18 de marzo de 2026, la empresa de inteligencia artificial MiniMax anunció la disponibilidad de M2.7, la iteración más reciente de su serie de modelos de lenguaje M2. El desarrollo de esta versión prioriza la capacidad del sistema para participar directamente en su propio ciclo de iteración y entrenamiento. A través de la construcción de entornos de agentes complejos, la gestión de memoria persistente y la ejecución de herramientas de búsqueda dinámica, el modelo fue configurado para actualizar su propia arquitectura de memoria de forma autónoma. M2.7 ya se encuentra accesible a través de MiniMax Agent y la plataforma API de la compañía.
Introducing MiniMax-M2.7, our first model which deeply participated in its own evolution, with an 88% win-rate vs M2.5
— MiniMax (official) (@MiniMax_AI) March 18, 2026
- Production-Ready SWE: With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%), M2.7 reduced intervention-to-recovery time for online incidents… pic.twitter.com/w21vUczxzV
Mecánica de autoevolución y flujos de aprendizaje por refuerzo
Un elemento central del reporte técnico es la implementación de un entorno (harness) de investigación de agentes diseñado para operar en entornos de trabajo heterogéneos y coordinar operaciones entre múltiples departamentos. Este sistema permite a una versión interna de M2.7 interactuar con diferentes grupos de proyectos de investigación dentro de la organización. A nivel de infraestructura, el modelo gestiona canales de datos (pipelines), configura entornos de entrenamiento y mantiene la colaboración entre equipos bajo las directrices establecidas por los investigadores.
En la práctica operativa del equipo de aprendizaje por refuerzo de la compañía, el modelo asume de forma autónoma múltiples etapas del ciclo de investigación. A partir de la discusión de una idea experimental, el agente automatiza la revisión de literatura, realiza el seguimiento de especificaciones predefinidas, consolida artefactos de datos y lanza los experimentos. Durante la ejecución de las pruebas, el sistema monitorea el progreso, perfila el rendimiento y activa automáticamente rutinas de lectura de registros, depuración de errores, análisis de métricas e inyección de correcciones de código mediante solicitudes de fusión (merge requests). Según el reporte de la empresa, M2.7 es capaz de procesar de manera autónoma entre el 30% y el 50% del flujo de trabajo de esta unidad.
Para lograr esta optimización autónoma, el modelo ajusta dinámicamente hiperparámetros operativos del sistema. En la decodificación de secuencias, el comportamiento exploratorio de los tokens se modifica alterando valores como la temperatura ($T$) en la función de activación softmax estándar:
$$P(x_i | x_{<i}) = \frac{\exp(z_i / T)}{\sum_j \exp(z_j / T)}$$
Al explorar el espacio de hiperparámetros, M2.7 busca empíricamente la combinación óptima de temperatura, penalización de frecuencia y penalización de presencia para tareas específicas. El reporte indica que el modelo ejecutó un ciclo iterativo de 100 rondas consistentes en analizar trayectorias fallidas, planificar cambios, modificar el código base del andamiaje (scaffold), ejecutar evaluaciones y comparar resultados para decidir la retención o descarte de las modificaciones. Durante este proceso, el agente diseñó flujos de trabajo específicos, como la búsqueda de patrones de errores idénticos en otros archivos tras aplicar un parche y la adición de detección de bucles infinitos en el código de ejecución. Estas acciones resultaron en un incremento del 30% en el rendimiento medido sobre conjuntos de evaluación internos.
Arquitectura de validación en competiciones de machine learning
Para validar las capacidades de autoevolución en escenarios de recursos restringidos, MiniMax condujo pruebas exploratorias utilizando el entorno de evaluación MLE-Bench Lite, publicado previamente en formato open-source por OpenAI. El modelo fue desplegado para participar en 22 competiciones de machine-learning que cubren todas las fases del desarrollo de modelos. La infraestructura de prueba se limitó a la ejecución en una única GPU NVIDIA A30.
El entorno diseñado para esta prueba consta de tres componentes principales integrados en el agente: memoria a corto plazo, retroalimentación propia (self-feedback) y autooptimización. Al finalizar cada ronda de iteración, el sistema genera un archivo Markdown consolidando su memoria y ejecuta un proceso de autocrítica sobre los resultados, proporcionando vectores de mejora para el siguiente ciclo. Tras tres ejecuciones independientes de 24 horas cada una, se reportaron las siguientes estadísticas:
- La mejor ejecución individual obtuvo 9 medallas de oro, 5 de plata y 1 de bronce.
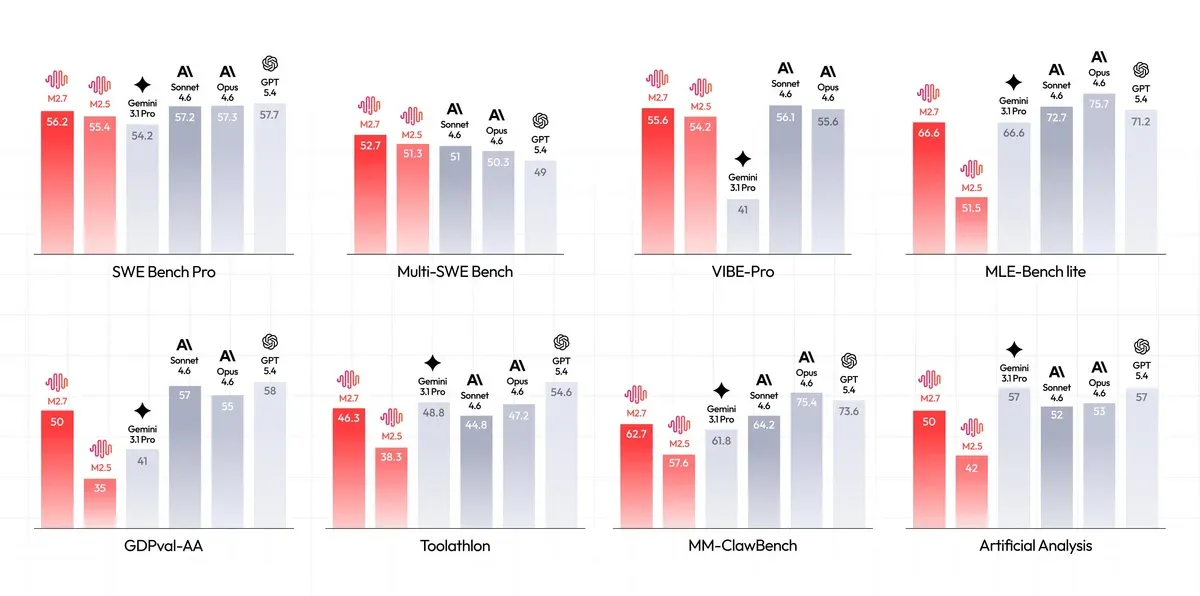
- La tasa promedio de obtención de medallas en los tres intentos fue del 66.6%.
- Este resultado empata con el rendimiento documentado de Gemini-3.1 (66.6%) y se posiciona por debajo de Claude Opus-4.6 (75.7%) y GPT-5.4 (71.2%).
Rendimiento en ingeniería de software y depuración en producción
En el dominio de la ingeniería de software, las métricas presentadas por MiniMax abarcan tareas de análisis de registros, auditorías de seguridad, refactorización y desarrollo multiplataforma. Las capacidades del modelo en la resolución autónoma de repositorios de código fueron evaluadas utilizando marcos estandarizados, demostrando paridad técnica con modelos frontera de la industria.
- SWE-Pro: 56.22% (Nivel reportado como equivalente a GPT-5.3-Codex).
- VIBE-Pro: 55.6%.
- Terminal Bench 2: 57.0%.
- SWE Multilingual: 76.5%.
- Multi SWE Bench: 52.7%.
- NL2Repo: 39.8%.
Un componente destacado de la implementación en producción es la capacidad de resolución de incidentes en entornos vivos (live debugging). Frente a alertas de sistemas de telemetría, el modelo correlaciona métricas de monitoreo con las líneas de tiempo de despliegue para establecer causalidad. Las acciones documentadas incluyen la realización de análisis estadísticos sobre muestreo de trazas, el diseño de hipótesis, y la conexión proactiva a bases de datos para aislar la causa raíz. El agente demuestra autonomía para identificar archivos de migración de índices faltantes en el repositorio y aplicar mitigaciones provisionales, como la creación de índices no bloqueantes para detener fallos críticos antes de iniciar una solicitud de fusión formal (merge request). MiniMax afirma que el uso de M2.7 en estos flujos de respuesta ha reducido el tiempo de recuperación de incidentes de producción a menos de tres minutos en múltiples ocasiones.
"Durante el proceso de iteración, nos dimos cuenta de que la capacidad del modelo para evolucionar recursivamente su propio entorno también es crítica. Nuestro entorno interno recopila retroalimentación de forma autónoma, construye conjuntos de evaluación para tareas internas y, basándose en esto, itera continuamente su propia arquitectura, implementación de habilidades/MCP y mecanismos de memoria para completar tareas de manera mejor y más eficiente."
Orquestación de equipos de agentes y aplicaciones ofimáticas
Para elevar la eficiencia en flujos de desarrollo complejos, M2.7 introduce soporte nativo para el paradigma de Agent Teams, facilitando la colaboración multi-agente. Esta arquitectura requiere que el modelo interiorice límites de rol definidos, capacidades de razonamiento adversarial contra sus homólogos y la toma de decisiones autónoma dentro de máquinas de estado finitas. En escenarios de prueba, la red de agentes fue capaz de anclar su identidad de rol y cuestionar puntos ciegos éticos o lógicos en las propuestas de otros agentes dentro del mismo enjambre de ejecución.
En las aplicaciones orientadas a tareas de oficina y procesamiento de lenguaje natural, el modelo fue evaluado en la métrica GDPval-AA, obteniendo una puntuación ELO de 1495, situándose por encima de GPT-5.3. La arquitectura permite la generación directa de archivos basada en plantillas y la ejecución de múltiples rondas de edición de alta fidelidad sobre documentos existentes de Word, Excel y PPT.
Las capacidades de interacción con entornos de sistema complejos (Tool use) fueron validadas mediante los siguientes indicadores:
- Toolathon: Precisión del 46.3%.
- MM Claw: Precisión general del 62.7% (aproximándose al nivel reportado para Claude 4.6 Sonnet).
- Adherencia a instrucciones: Tasa de cumplimiento del 97% al ejecutar más de 40 habilidades de sistema complejas, donde cada instrucción superaba los 2.000 tokens de longitud.
Para ejemplificar estas capacidades, la empresa documentó un caso de uso enfocado en la modelización financiera. En esta tarea, M2.7 procesó de forma autónoma los reportes anuales y las minutas de las llamadas de ganancias de la empresa de semiconductores TSMC. El agente fue capaz de cruzar referencias provenientes de múltiples informes de investigación, diseñar supuestos de mercado, construir un modelo de predicción de ingresos, y consolidar los datos finales en documentos de presentación (PPT) y reportes de investigación (Word), ajustando el resultado a través de correcciones interactivas.
Consistencia de personajes y desarrollo de interfaces interactivas
El reporte concluye detallando mejoras en la consistencia de personajes y el manejo de conversaciones abiertas, orientadas al sector del entretenimiento y las interfaces de usuario de nueva generación.
Bajo este enfoque, MiniMax ha publicado el código de una demostración denominada OpenRoom, un sistema de interacción estructurado sobre el entorno del agente. Esta implementación abandona las salidas de texto plano en favor de un espacio interactivo de interfaz gráfica web (Web GUI). Dentro de este entorno, la configuración de la personalidad de los agentes modifica en tiempo real la retroalimentación visual del sistema y las interacciones espaciales de la escena, permitiendo que los modelos respondan de manera proactiva a los elementos de su entorno. Gran parte del código base de esta interfaz fue escrito de forma autónoma por los propios modelos de inteligencia artificial de la compañía.
Recursos y enlaces
- MiniMax Agent: agent.minimax.io
- Plataforma API: platform.minimax.io
- Coding Plan: platform.minimax.io/subscribe/coding-plan


